This is the first article on Monney Works. It documents why I wanted to build the blog and how it went from idea to live on monneyworks.com in less than 4 hours.
Why I wanted to build this
I started following Fábio Akita, a well-known Brazilian software veteran, only recently. In March, he wrapped up a cycle he called "37 days of vibe-coding immersion" — 37 days building project after project with Claude Code and documenting each one. At the end, he published an article and a video summarizing the run: 653 commits, 144 thousand lines of code, 8 projects in production, among them the refoundation of his own blog, which just turned 20 years old online.
What caught my attention in the video was the volume and quality of projects he shipped in such a short window. It made it very concrete, for me, how big the opportunity is right now in software architecture and development.
I have a lot of ideas. Application MVPs, digital business strategies, the proprietary methodology I call Arquitetura de Escala, studies on whatever catches my curiosity. I always did. The difference is that, until recently, getting an idea out of your head demanded weeks of manual setup: configuring tooling, deciding a stack, writing boilerplate, fighting typecheck, dealing with incompatible libraries, migrations, build pipeline. The blocker was never "not knowing". It was "not having the time to go through all of that again."
LLMs changed that point. They did not remove the obligation to understand what you're building — I still demand intentional architecture, strict types, tests that run before the code, real i18n instead of duct tape. What changed is that the loop between having the idea and having the prototype running shrank from weeks to hours. Today, if you know what you want, you can build it.
What I was missing, with the ideas I'd been accumulating, was the place to put all of it. I decided that place was going to be Monney Works — a bilingual asset, indexable by Google in the reader's native language, that would work as raw material for every other communication format I produce.
How it started
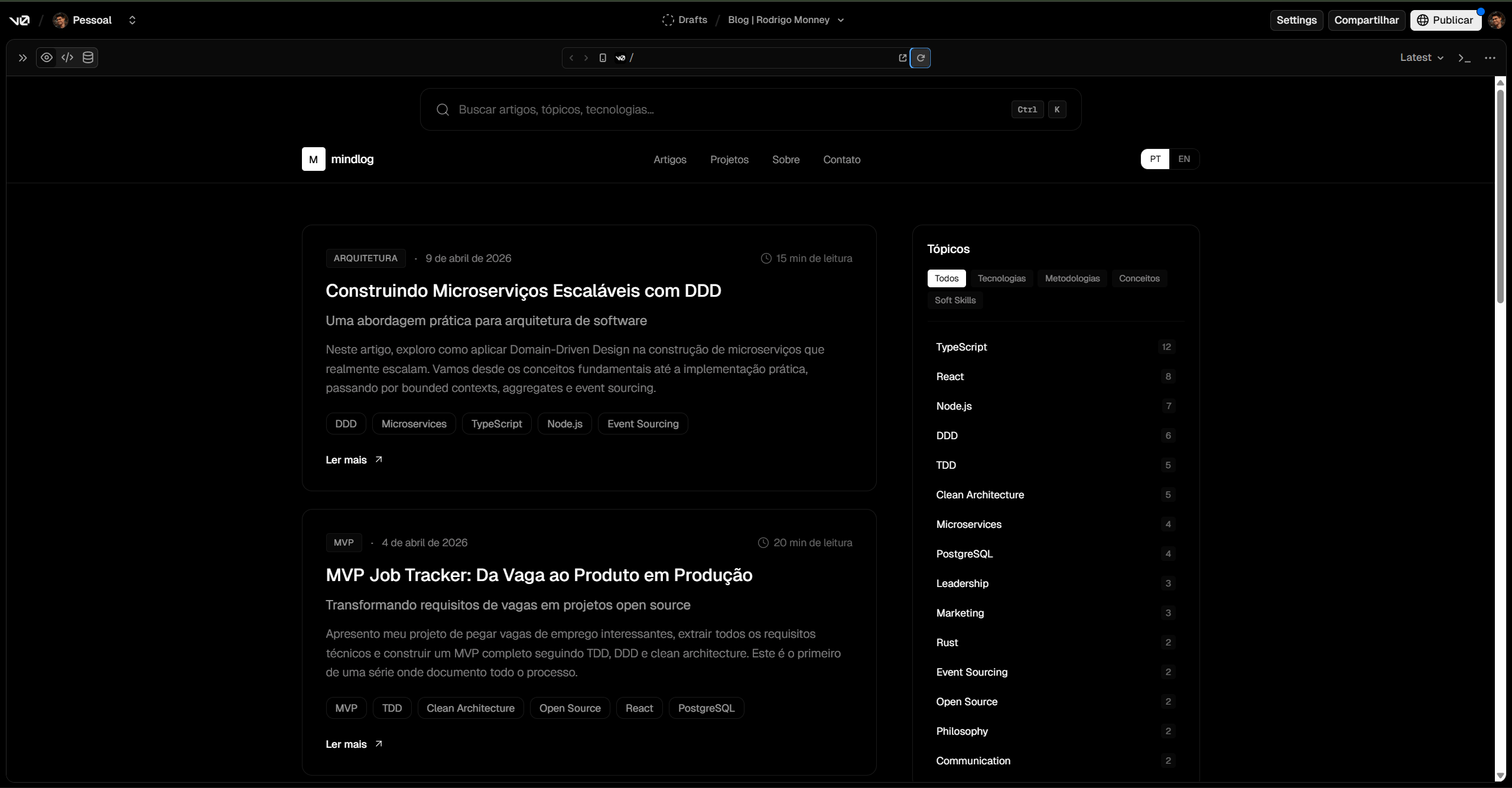
Before writing a single line of code, I used Vercel's V0 to prototype the visuals. I knew what I wanted — a centered search bar with a liquid-glass effect (inspired by this video), black and white, article list taking up two thirds of the screen with a topics sidebar on the right, minimalist throughout. But before investing energy in real implementation, I wanted to see the idea running in the browser.
The initial blog draft in V0, still under the working name "mindlog" which I later dropped
Once the draft was close to what I had in my head, it was time to leave the prototype behind and build it the right way. I downloaded the generated code, opened it in VS Code with Claude Code, and that's when the real project started.
The V0 code was more or less what I expected from a mock: hardcoded mock data in lib/mock-data.ts, ignoreBuildErrors: true in next.config (meaning typecheck errors were being hidden instead of fixed), i18n implemented as a Context with useState instead of a real internationalization solution, zero tests, no separation between domain and presentation. The structure served to navigate and validate UX, and that's exactly what a mock is for. It just wasn't going to production as the foundation of a project of mine.
So I applied the guidelines I already use on real projects: my CLAUDE.md, a file where the architecture rules live — the project conventions, the Domain-Driven Design principles, the strict TDD rules, the requirement of small phases (at most five files at a time) with typecheck, lint and test verification before advancing, and the granular commit policy. I sketched a plan together with Claude Code, adjusted it until it looked the way I wanted, and started the implementation.
What I wanted from the blog
Before writing a single line, what matters is the idea. Mine was clear:
Minimalist and elegant. Black and white, no fluff. Focus on the text, on modern components, on the translucent-glass search bar pinned across every page.
Markdown-first, with study turning into article. The baseline flow is this: whenever I'm developing a project, going deeper into a methodology, or studying a topic that interests me, I create a draft markdown file. I dump everything in there — what I know, what I want to learn, the angles I want to explore. Then I ask Claude to put together a study plan connecting what I wrote to the areas of knowledge that interest me. A concrete example: recently I rewatched the first Spider-Man, the 2002 one with Tobey Maguire, for the first time in about 15 years. One scene in particular caught my attention — Willem Dafoe playing Norman Osborne and the Green Goblin dialoguing in the mirror, two opposite characters sharing a scene with no cut. That made me want to analyze the scene crossing NLP, the shadow archetype in Jung, and the idea that the Green Goblin showing up is Norman confronting his darker and more perverse side. It became study material, and it will turn into an article here soon. The idea is this: take what I learn in personal and professional projects and share it, in my own way. The rest of the pipeline — generating the slug, translating to the other language, organizing the chronological folder, finding related articles — is automated by a Claude Code skill that processes the draft.
Bilingual from day one. pt-BR and English, localized URLs (/pt-BR/... and /en/...), each article living as two files (pt-BR.md + en.md) in the same directory. Spanish and European Portuguese come later, but the architecture already has to handle it.
Git-based admin. I'm the only admin. But "access" here isn't a login into a dashboard — it's git commit + git push. Vercel detects the push, rebuilds the site, and the new content is live.
Code on GitHub. Versioned, traceable, openable later if I want. More importantly: the blog is where I apply, on a project of my own, the same patterns I use professionally — DDD, TDD, strict types.
Why not continue with the V0 code as is
V0 is great for prototyping and wasn't built to be the foundation of what goes to production. The mock's architecture assumes things that simply don't hold up in a project that needs to last.
When I think of a "real project", I'm not talking only about running on a local machine. It's about code that needs to be deployable, secure, observable, with room to scale. That can start small but needs to absorb growth. Especially if the project is going to have real users — and even more so if it handles third-party data. Non-negotiable concerns kick in then: authentication, encryption of data in transit and at rest, clear separation between layers, tests covering the critical behavior, auditability.
The idea isn't to architect a monster from day one. It's to reason, from the very first decision, about what makes sense and what doesn't so that the project can evolve without turning into rework. Architectural decisions made early become entrenched — changing them later costs much more than paying the cost now.
The V0 mock failed this filter in four places:
Mocked data instead of a real persistence layer. The classic "I'll just swap it later" tends to postpone a migration that, in practice, never happens.
ignoreBuildErrors: true on the build. That means typecheck errors were being silenced instead of fixed. And static typing only has value when a type error breaks the build.
Context + useState as i18n. It works to toggle strings at runtime, but it doesn't support localized routing (/pt-BR/..., /en/...) nor real multilingual SEO.
Zero tests. No guarantee that the next change won't break what was already working.
Each of those points, if it slipped into the main project, would become tech debt in a matter of days. I'd rather spend the right time upfront than pay the compound rate later.
How the application is structured
The application is built in four separate layers, following Clean Architecture and Domain-Driven Design principles. Each layer has a clear responsibility and depends only on contracts defined by inner layers.
Domain — the core. Represents the business concepts (article, tag, category, publish date, reading time) without knowing anything about the rest of the world. Doesn't depend on Next.js, doesn't depend on files, doesn't depend on a database.
Application — the use cases. They orchestrate the domain and consume its contracts (list articles, get by slug, find related, list topics).
Infrastructure — the bridge to the outside world. Implements the contracts defined by the domain. In this blog, it reads markdown files from the filesystem and translates them into domain objects.
Presentation — the Next.js layer. App Router pages, React components, DTOs that cross the server → client boundary.
This separation keeps what is business rule away from what is implementation detail. If tomorrow the articles leave the filesystem and move to a database, only the infrastructure layer needs to change — the domain, the use cases, and the pages stay intact.
Development was executed in small phases, each touching at most five files, with granular commits and automated verification (npx tsc --noEmit for typecheck, npm test for tests, npm run lint for static analysis) before moving on. The 32-commit history in the repository shows that cadence — no commit represents more than one closed and verified unit of work.
How I rebuilt it, phase by phase
Phase 0 — Bootstrap. Project setup: Next.js 16, React 19, strict TypeScript with noUncheckedIndexedAccess (strict array access checking), noUnusedLocals, and noUnusedParameters turned on. Tailwind v4. ESLint with flat config. Prettier. Vitest for tests. No ignoreBuildErrors — typecheck errors fail the build.
Phases 1 and 2 — Domain.Article is the aggregate root — in DDD, the entry point of the aggregate, the entity that ensures all business rules related to an article are respected. It's identified by its Slug.
Around it live the value objects: Slug, Tag, Category, PublishDate, Locale, LocalizedText, ReadingTime. Value object is a DDD concept for representing values without their own identity — one publish date is the same as another if they're the same day, unlike two articles which, even with the same title, are distinct entities.
Each value object has a private constructor and a static factory that validates data before allowing creation. That means an Article in memory is never in an invalid state — there's no article with empty tags, unknown category, or malformed date. If construction passes, the object is trustworthy from that point on.
Tests come before implementation. The cycle is the classic red-green-refactor: first you write a test that fails (red), then the minimum code to make it pass (green), then you refactor while keeping the tests green (refactor). This inverts the natural order of development — code is born answering to an expected behavior, not the other way around — and as a side effect it produces full coverage of what was implemented.
The ArticleRepository and ArticleIndex contracts live in the domain only as types, with no implementation. The domain layer has no idea whether articles come from markdown files, from Postgres, or from a remote API. The infrastructure decides, and that decision can change in the future without the domain needing to know.
Phase 3 — Markdown infrastructure. Here enters the concept of anti-corruption layer (ACL), a protective layer between the domain and the outside world. Data that comes from outside (in this case, the YAML at the top of markdown files) needs to be translated and validated before becoming domain objects. If any data is outside the expected shape, the ACL rejects it at the boundary, before the problem reaches the inner layers.
In the blog, that layer is frontmatter-parser.ts. It takes a pair of files (pt-BR.md + en.md), uses the gray-matter library (a parser that separates the YAML header from the markdown content) to extract the metadata, and translates each field into the corresponding value object. If the category comes outside the accepted enum, a tag comes empty, or the date comes malformed, the parser fails immediately with a clear message, and no invalid object reaches the domain.
markdown-article-repository.ts implements the contract defined by the domain. It walks content/articles/YYYY/MM/{slug}/, reads both files in parallel with Promise.all, and returns the articles ready. When something fails, the error surfaces with the path of the failing directory, which makes it easy to find which file broke the build.
Phase 4 — Use cases. Five short use cases: listArticles, getArticleBySlug, searchArticles, findRelatedArticles, listTopics. All of them take the repository via dependency injection — meaning the application layer doesn't instantiate anything, it just asks for what it needs. Every test uses an in-memory fake instead of touching the filesystem, and the full suite, with 145 tests, runs in under two seconds.
Phase 5 — i18n. The next-intl library handles localized routing (/pt-BR/... and /en/...). The list of supported locales comes straight from the domain — the same Locale that validates articles is what configures the routing. That way, there's no chance the routing layer drifts away from the rest of the application.
Phase 6 — Layout. App Router scaffold with translation provider, Geist and Unbounded fonts, header and footer. The first next build generated the static routes.
Phase 7 — Functional home. V0 visual components ported on top of the real domain. A composition root (src/infrastructure/container.ts) instantiates the repository with the articles root path and exposes the use cases ready to be consumed. A DTO (ArticleView) flattens the domain objects at the server → client boundary — domain classes don't cross that boundary, only serializable primitive data.
Phases 8 to 13 — Everything else. Individual article page rendering markdown via react-markdown + remark-gfm (an extension that enables tables, task lists, and other conveniences from GitHub Flavored Markdown) and a custom plugin (remark-highlight) that turns ==text== into a <mark> with the brand color. Tags got a URL-safe slug (Clean Architecture → clean-architecture) and their own pages at /topics/{tag}. Sitemap and robots.txt with hreflang — the meta tags that tell Google that the URLs in pt-BR and English are versions of the same page in different languages, so neither gets penalized as duplicate content. Search bar promoted from a home component to the global layout, appearing pinned across every page. Animated canvas particle field reacting to the cursor. GlassSurface with an SVG displacement filter giving real liquid-glass feel to the cards and the search bar. Lottie confetti that fires only on this article's page — the celebration is specific to the first post. Localized OpenGraph/Twitter metadata, metadataBase pointing to the final domain. Vercel deploy. Domain monneyworks.com pointed.
In practice, this means the page of this article is built by passing through the domain, the parser, the repository, the use case, the Next page, and the React components — every layer doing its part.
The publishing workflow I wanted
What made me want to build it this way was the vision of the publishing flow. It works like this:
I have an idea. I open a file in content/_drafts/ (a git-ignored, private directory inside the repo itself). I dump loose notes in there, a project draft, snippets from an MVP I'm designing — whatever.
When it's ready, I run /publish-article content/_drafts/foo.md in Claude Code.
The skill reads the draft, suggests slug, category, and tags, translates to the other language while preserving code blocks and technical terms, calculates reading time, finds related articles by tag overlap, and shows me a full preview.
I approve. The skill moves the files to content/articles/2026/04/{slug}/pt-BR.md + en.md, runs npm run typecheck and npm test, and asks if I want to commit.
git push. Vercel rebuilds. Article is live.
My job is what I know how to do: have ideas and draft them. The automation takes care of the rest.
What's going to live here
I have a lot of ideas. Application MVPs — Split Reel, for instance, a project that syncs the computer screen recording with the phone camera and exports it as a vertical reel, phone camera on the bottom, screen on top. MVPs built from real job postings — I take the technical requirements of a concrete posting, architect the whole application, and leave it running for anyone to try. Business strategy based on the proprietary methodology I've been developing and call Arquitetura de Escala — the communication, offer, acquisition and retention structure I use to build digital businesses from zero. Studies on whatever catches my attention — architecture, philosophy, persuasion, leadership, marketing, cinema.
The blog is the central asset. Every article I publish here is raw material for dozens of other communication formats — social cuts, video scripts, a starting point for a talk, a sales argument. One dense, well-thought, documented piece in two languages indexable by Google in the reader's native language turns into everything else with a fraction of the work. I write once, and the rest is propagation.
One thing I want to make clear: I don't have the ambition of being a writer. I have the ambition of having what I think recorded. The idea of every article comes from me, the curation is mine, the decision of what to publish is mine. If something landed on this domain, it's because I investigated, learned, and agree. The LLM is the tool that helps me turn the idea into text — not the source of what I think.
Over time this becomes a portfolio: documented projects, methods explained, decisions justified, ideas refined in public. That's what I want to build.
First of many
Between the moment I downloaded the V0 code and the moment this article went live, less than 4 hours passed. The whole thing exists — monneyworks.com resolves, SSG serves the pages in pt-BR and English, the sitemap lists every article with hreflang alternates, and, if you're reading this, the confetti fired when the page loaded.
This is the first article of many.
The next one comes with the next project — or with the next crazy idea my head comes up with.
Where the tokens go — the real cost of a Claude Code session
What I found reading the transcripts of my own sessions
Instead of guessing where my token cost went, I read the logs of my Claude Code sessions. This article shows the method, the numbers I found, and what they say about when and how to compact context.